OpenAI financiou discretamente benchmark independente de matemática antes de quebrar recorde com o3

O envolvimento da OpenAI no financiamento do FrontierMath, um benchmark líder em matemática para IA, só veio à tona quando a empresa anunciou seu desempenho recorde no teste. Agora, o desenvolvedor do benchmark, Epoch AI, reconhece que deveria ter sido mais transparente sobre a relação.
Introduzido em novembro de 2024, o FrontierMath testa como os sistemas de IA lidam com problemas matemáticos complexos que exigem habilidades avançadas de raciocínio e resolução de problemas, tarefas que geralmente desafiam até os sistemas de IA mais sofisticados. Os problemas do benchmark foram criados por uma equipe de mais de 60 matemáticos líderes.
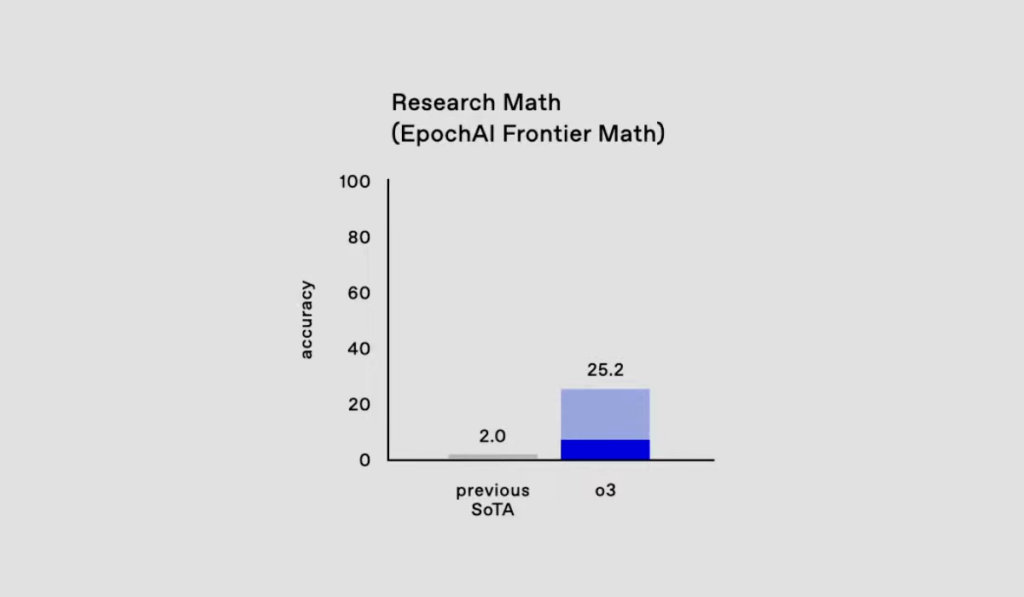
A conexão entre OpenAI e FrontierMath foi revelada em 20 de dezembro, no mesmo dia em que a OpenAI apresentou seu novo modelo o3. O sistema alcançou uma taxa de sucesso sem precedentes de 25,2% nos desafiadores problemas de matemática e lógica do benchmark, um salto enorme em comparação com modelos anteriores que não conseguiam resolver mais de 2% das questões.
A Epoch AI, que desenvolveu o benchmark, havia assinado um acordo que a impedia de revelar o apoio financeiro da OpenAI até o anúncio do o3. Eles reconheceram a conexão em uma nota de rodapé após atualizar seu artigo de pesquisa pela quinta vez, afirmando simplesmente: “Agradecemos à OpenAI pelo apoio na criação do benchmark.”
De acordo com uma postagem no LessWrong, os mais de 60 matemáticos que ajudaram a criar os problemas do benchmark não sabiam do envolvimento da OpenAI, mesmo após o anúncio do o3. Embora esses especialistas tivessem assinado acordos de não divulgação, os acordos cobriam apenas a manutenção da confidencialidade dos problemas. A maioria acreditava que seu trabalho permaneceria privado e seria usado exclusivamente pela Epoch AI.
OpenAI tem acesso a “muitos, mas não todos” os dados do benchmark FrontierMath
Tamay Besiroglu, da Epoch AI, admite que cometeram erros. “Deveríamos ter pressionado mais para a capacidade de sermos transparentes sobre essa parceria desde o início, especialmente com os matemáticos que criaram os problemas,” escreve ele.
Segundo Besiroglu, a OpenAI teve acesso a muitos dos problemas e soluções matemáticas antes de anunciar o o3. No entanto, a Epoch AI manteve um conjunto separado de problemas em segredo para garantir que o teste independente ainda fosse possível.
Eles também fizeram um acordo verbal com a OpenAI que proíbe a empresa de usar os materiais para treinar seus modelos, uma salvaguarda contra a manipulação do benchmark e para evitar que os problemas se tornem públicos.
“Para futuras colaborações, nos esforçaremos para melhorar a transparência sempre que possível, garantindo que os colaboradores tenham informações mais claras sobre as fontes de financiamento, acesso aos dados e propósitos de uso desde o início,” escreve Besiroglu.
Embora essa falta de transparência não comprometa a qualidade ou a importância do benchmark, uma ferramenta tão importante para a avaliação de IA merecia total abertura desde o início, especialmente porque o raciocínio matemático é uma grande fraqueza dos modelos de linguagem e o melhor desempenho lógico poderia sinalizar um avanço.
“Acredito que a OAI tenha sido precisa em seu relatório, mas a Epoch não pode garantir isso até avaliarmos independentemente o modelo usando o conjunto de retenção que estamos desenvolvendo,” escreve o matemático líder da Epoch AI, Elliot Glazer.
A situação destaca como o benchmarking de IA se tornou complexo. Criar esses benchmarks é um trabalho caro e intrincado. Embora os resultados dos testes possam ser difíceis de traduzir em desempenho no mundo real e dependam fortemente dos métodos de teste e da otimização do modelo, esses mesmos resultados desempenham um papel crucial na atração de atenção e investimento.
Fonte: The Decoder



Publicar comentário